Storage Segment Prediction with Deep Learning (segmentseq2seq)
Table of Contents
- Overview
- Introduction
- Block2Vec High Level Overview
- Segmentseq2seq Design and Implementation
- Prediction Results
- Conclusion and Future Work
Overview
This project addresses the problem of predicting storage segment sequences using deep learning. Given a stream of block accesses as seen by the block storage, the project tries to predict accurate segment accesses based on access context. Compared to the Block2Vec paper (which was the source of inspiration for this project), the number of round trips to the underlying storage is about 30 times lesser - to make a prediction. Implementation of Storage Segment Sequence predictor can be found here on Github.
Introduction
Accurate prediction of block accesses has many uses, and increased speed of the storage system as a result of better caching is one of the primary advantages. Other uses could include intelligent cleaning of a Log Structured Journal, reduction in overall cost of the storage system due to reduction in main memory sizes for caching purposes etc. Direct incorporation into an existing archival storage system is probably the lowest hanging fruit. Given that restoration from a backed up system does not involve change in access patterns, this trained model can be directly incorporated into an existing archival/secondary storage systems, for immediate benefits. Further, frameworks like TensorFlow have in-built support for distributing its computation graph across a cluster. A scale out storage system could take advantage of this, to partition the training of model on the generated traces and to make predictions on unseen block sequences.
This project takes advantage of the pre-processing techniques mentioned in the Block2Vec paper (see below for a high level overview) to generate the required block vocabulary, block sequences inputs and labels, for the model to be trained upon. Given that most storage systems don’t access a single block upon a request, and given that they access a chunk of blocks in one go, in addition to the pre-processing techniques mentioned above, this project reduces a block access to its nearest lowest multiple of the chosen segment size. For example, if the segment size = 4096 and a request to block offset 3584 is made, it would be reduced to an access to segment 0. Doing so results in reduction of the vocabulary size, reduces training time, reducess loss to less than 1, and improves prediction accuracies.
Block2Vec High level Overview
Block2Vec paper aims at building a model that describes the probability of accessing a specific group of blocks together. Instead of using just the block ID/offset to represent a storage block, Block2Vec uses an N dimensional vector to represent a storage block. The idea is that the N dimensional vector would be able to represent many features of the block. For example, the vector might be able to represent the physical location of the block, its create, access times, its owner etc. Thus, similar to how Word2Vec learns word vectors and word context vectors, Block2Vec would end up learning block vectors and block context vectors. After training, blocks that are semantically close end up clustering together. The model’s prediction accuracy is evaluated by searching for N=30 most similar blocks in the higher dimension space. If one among the 30 blocks happens to be the next to-be predicted block, the paper considers it as an accurate prediction. Doing so, results in accuracies in the 75-80% ranges with the use of Skip gram. Corresponding accuracies for the compared Sequential Prediction (SP) model in the Block2Vec paper lie below 25%.
Segmentseq2seq Design and Implementation
Word2Vec needs a list of sentences with words. Words are indexed and a vocabulary is created out of it with F most frequently used words. Words that are used less frequently than F are treated as out-of-vocabulary words. Figure 1 below shows a plot of block offsets and the number of times those offsets are accessed. Note that the frequency of access after block offset 1 million is almost zero in the case of UMass OLTP block traces. These traces were obtained from OLTP applications running at two large financial institutions.
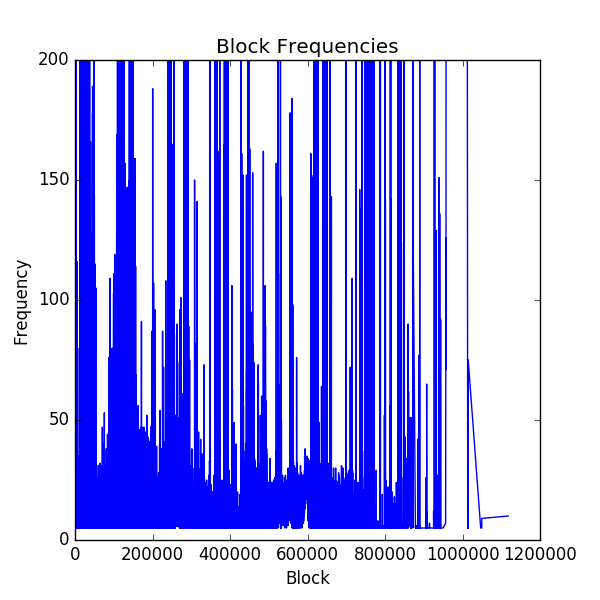 Fig. (1) UMass OLTP traces block access frequencies
Fig. (1) UMass OLTP traces block access frequencies
For a given target word T, words from a window of size W are used as labels and these (target,label) pairs are fed to the unsupervised learning model - Word2Vec. Similarly, Block2Vec considers each offset/block as a word (disregarding the size of the read/write access) and creates sequences out of these blocks accesses in a specified window of time. For example, a sequence could be created out of all block accesses that are 1 minute apart. Figure 2 below shows a plot of block sequences (sequence of block offset accesses) that occur within a 64 millisecond window of time. Note that the number of sequences which contain blocks that are accessed within a 64 millisecond window of time is almost close to zero after 20 block length sequences.
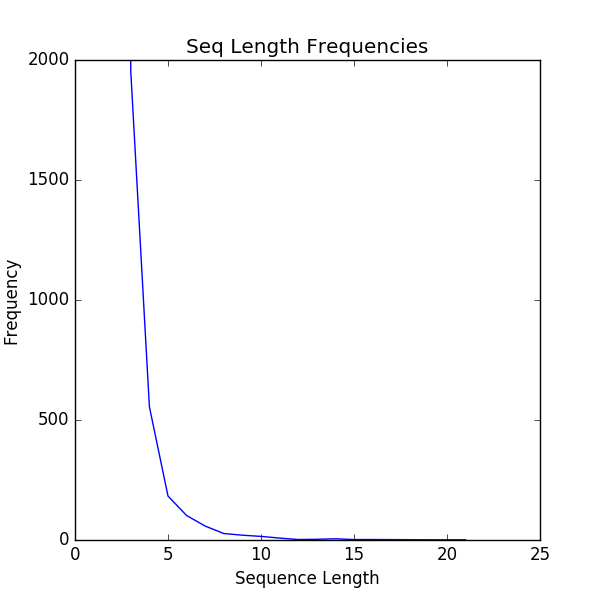
Fig. (2) UMass OLTP traces - 64 millisec access window sequence length frequencies
So as to give more importance to block accesses that are close to each other, sentences are created by repeatedly halving the specified window of time. At a very high level, Block2Vec performs pre-processing on MSR traces as mentioned above so as to create inputs and labels fit for training.
The segmentseq2seq model takes the idea of Block2Vec further and tries to predict a fixed length sequence of blocks - given a fixed length sequence of input blocks, as opposed to searching for the 30 nearest blocks in a higher dimension space of a given block and hoping to find the next accessed block among those 30. To do so, segmentseq2seq leverages work from the Sequence to Sequence Learning with Neural Networks paper. Tensor flow has a nice tutorial and an example implementation as well on Seq2Seq models. For more details on Recurrent Neural Networks, see these excellent blog posts 1 and 2.
Credits: segmentseq2seq leverages a lot of code from Suriyadeepan’s practical seq2seq. In the original Sequence to Sequence learning paper, at training time, a corpus that consists of English (input) to French translations (labels) is fed to the model. In the case of segmentseq2seg model, at training time, a sequence of segment IDs (inputs) accessed in a window of time, and a shifted by one sequence of segment IDs (labels) from the input sequence are fed to the model.
Given that most storage systems have a level of abstraction over blocks, and given that a storage device’s access usually involves access of a chunk that contains more than one block, for the purposes of segmentseq2seq, such an abstration is called a Segment. Size of the segment is a hyperparameter and block IDs/offsets are reduced to corresponding segment IDs (because such a segment ID is not readily available in the traces) in the inputs and labels. In a real system, a real segment/chunk ID could be used. Segment IDs are projected into a higher dimensional space and their embeddings are learned with back propogation during training. Reducing block IDs/offsets, reduces the vocabulary size drastically, results in faster training, lower validation loss and better accuracies.
Prediction Results
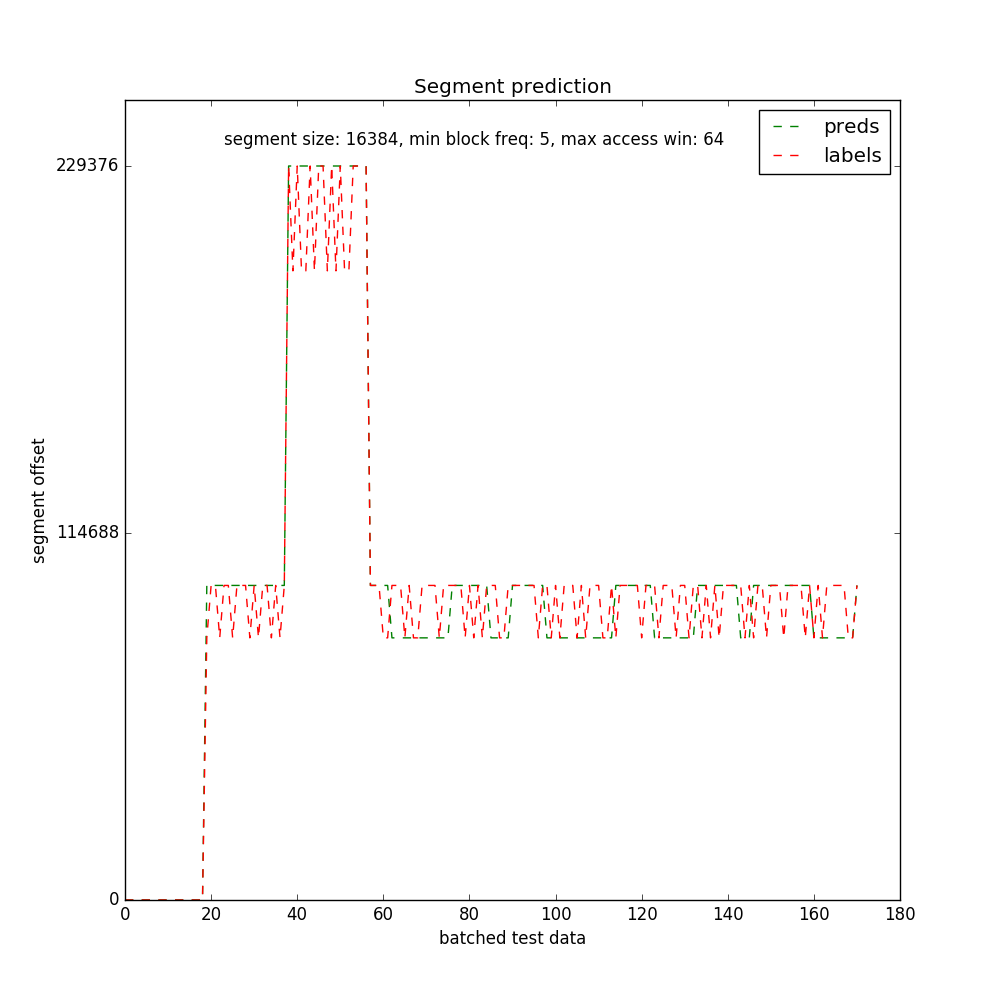
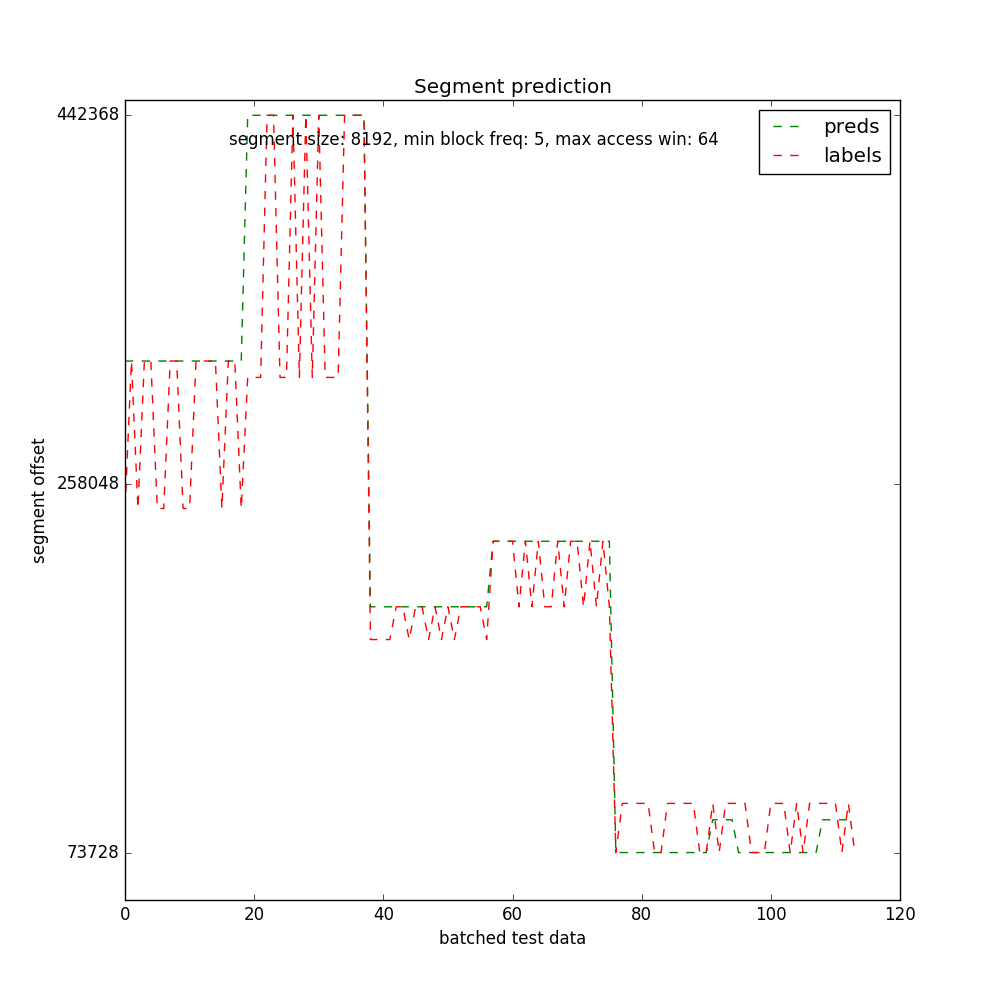
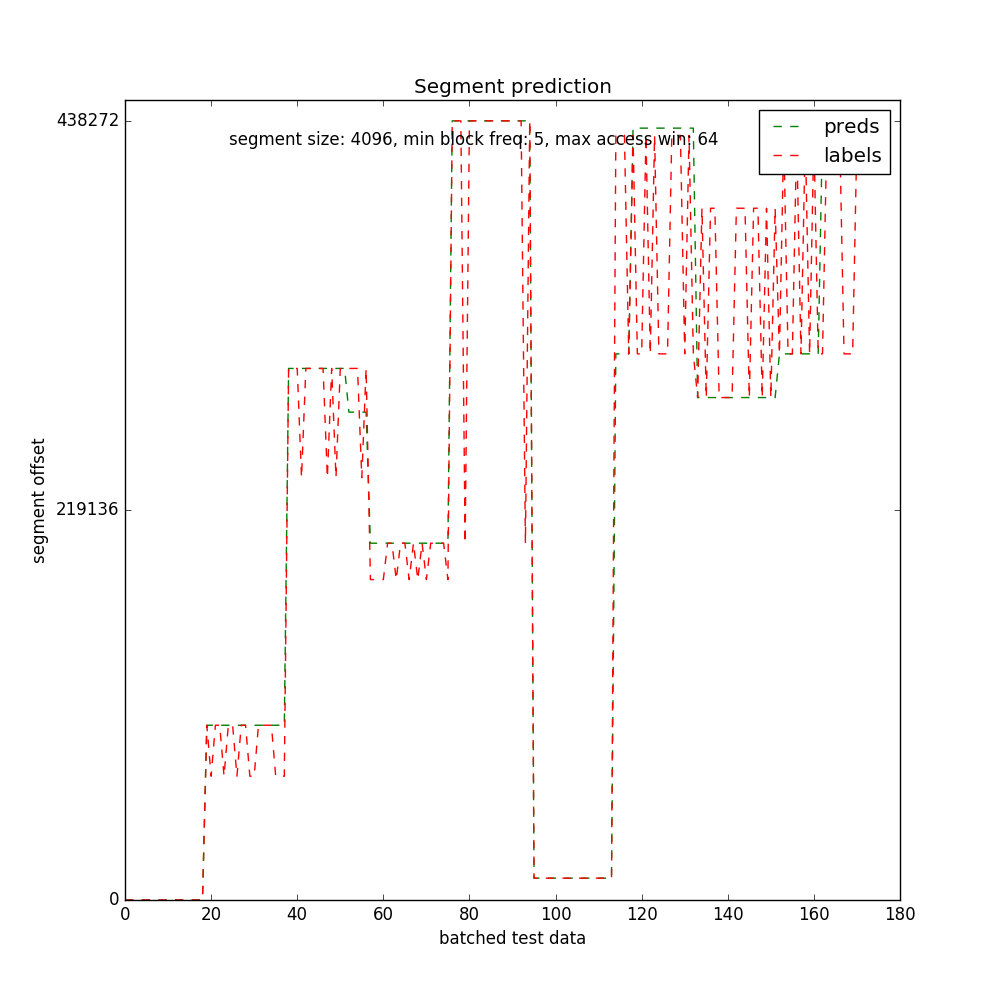
Finally, the results. As the segment sizes are increased, more block offsets fall into a segment thereby reducing the vocabulary size of the model. Lower vocabulary sizes result in smaller embedding matrices and faster training. With segment sizes of 16k and 8k, I could train until the validation loss fell below 2.0 and 1.0 respectively, resulting in better accuracies than with 4k segment sizes. With 4k segment sizes, the validation loss went down until 2.8 and continued to be constant there. More patience and longer training perhaps would have resulted in better accuracies in the case of 4k segment sizes.
Segment Size (16k):
Segment Size (8k):
Segment Size (4k):
Conclusion and Future Work
To the best of my knowledge, this is the first time that a deep learning based Recurrent Neural Network has been used to learn storage segment sequences and thereafter make predictions on unseen segment sequences. Design, implementation and results of the project along with the code, trained model checkpoints and preprocessed datasets have been discussed and made publicly available. The model can be reused for other block traces by making necessary changes to the data utilities module.
The limited amount of GPU memory prevented me from running the sequence to sequence model with attention. With attention, the accuracies should hopefully go up.